
HyperFinity 如何利用 Snowflake 的 Snowpark for Python 简化其无服务器架构
HyperFinity 是一个决策科学 SaaS 平台。通过机器学习和人工智能、嵌入式分析和数据可视化,HyperFinity 使非技术用户能够做出数据驱动的决策,并创建简单的输出以支持下游系统,例如 CRM、ERP 或内容管理系统。这使得组织能够快速地在多个领域做出由机器学习驱动的决策,从更智能的供应链到优化的定价。
Snowflake 是 HyperFinity 数据密集型平台的核心。除了广泛的数据类型支持(例如半结构化数据的变体数据类型)之外,Snowflake REST API 和零拷贝克隆等其他功能在平台的无服务器架构中也发挥着宝贵的作用。Snowflake 的安全数据共享还简化了 ELT 流程,并简化了 HyperFinity 平台及其输出与已经使用 Snowflake 的客户的集成。
挑战:不同编程语言采用不同的基础设施
虽然 HyperFinity 的平台是为非技术用户设计的,只需点击一下即可轻松应用机器学习和人工智能,但所有所需的数据处理功能都是由专注于数据科学的团队开发的,他们的主要编码语言是 SQL 和 Python。Snowflake 处理了我们所有的 SQL 开发和处理,但为了为我们的 Python 代码构建一个无服务器计算引擎,我们的团队必须在 AWS 上建立一套新的云基础设施,这需要将多个计算服务(如 Amazon EC2 和 AWS Lambda)连接起来。这有几个缺点,例如不得不将数据移出 Snowflake 的治理边界进行处理,维护额外的基础设施,以及编写额外的代码来处理服务之间数据结构的变化。
当我们看到Snowpark 对 Python 的支持发布时,我们对它可能带来的可能性感到非常兴奋,我们也非常幸运地参与了私人预览。
使用 Snowpark for Python 简化我们的架构
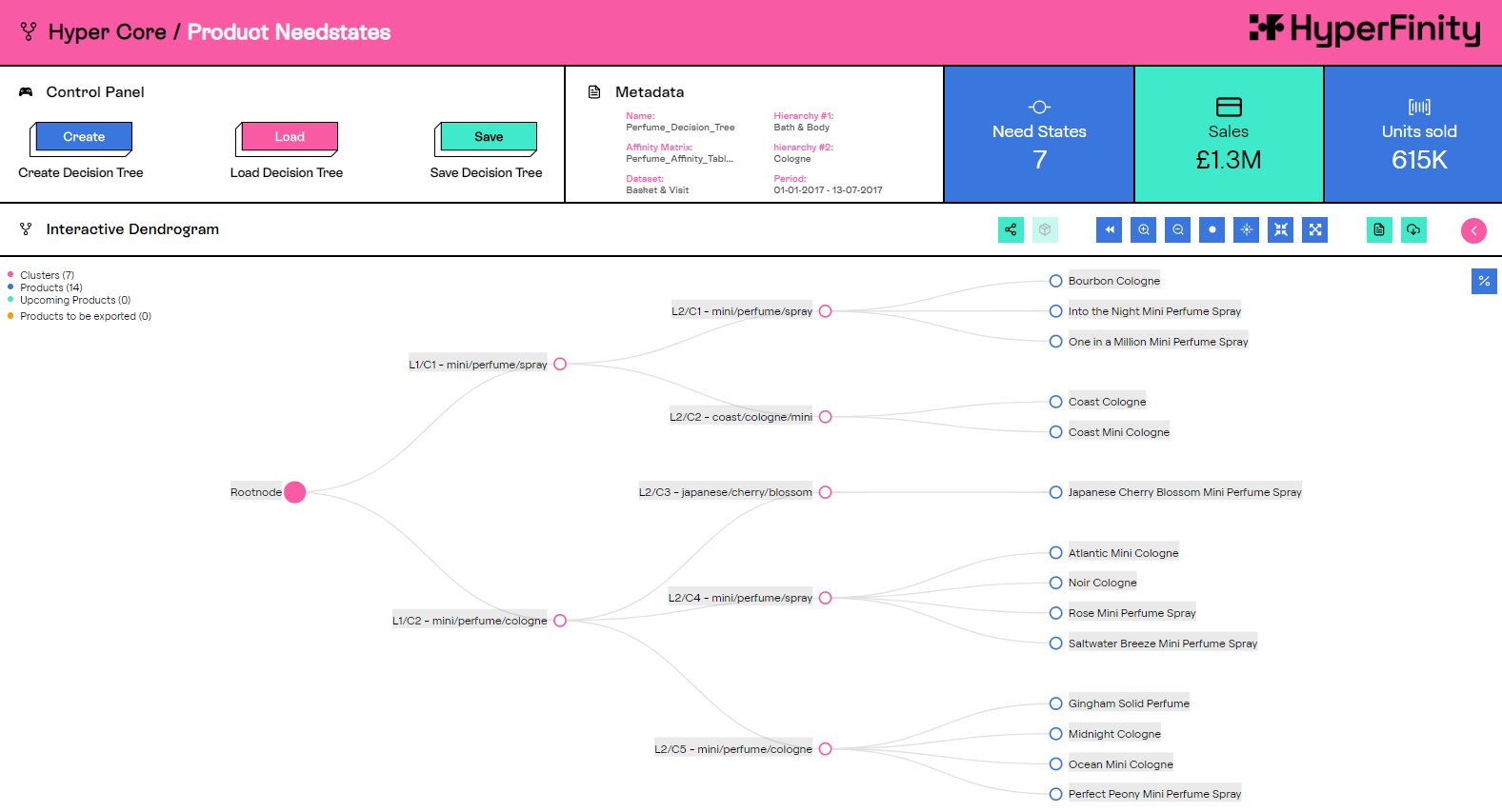
Python 的优势之一是其丰富的开源包和库生态系统,我们广泛使用了这些包和库。例如,平台的核心部分是为产品组创建“客户需求状态”。这使用了一种称为层次聚类的技术来创建客户决策树,它表示个人为购买产品而做出的选择。计算这些需求状态需要矩阵和数组乘法,我们的团队在 Snowpark 中使用 Python 库 numpy 和 scipy 利用了这一点。通过使用 Snowpark,这种类型的计算在 Snowflake 中开发和实现要简单得多。
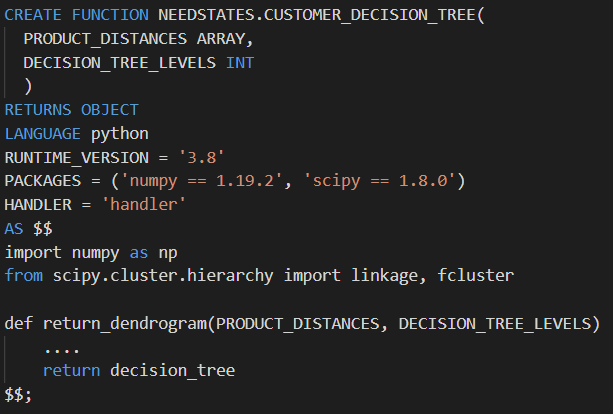
以前用于 Python 处理的云基础设施被简单的 Snowpark 代码取代
由于 Snowpark for Python 环境通过 Snowflake 与 Anaconda 的合作预装了 1,000 多个库,我们可以轻松地迁移现有功能,只需极少的精力。拥有最流行的库可以消除开发过程中的另一层管理,并且通过集成的 conda 包管理器,无需担心依赖管理。如果我们需要自定义库,Snowflake 支持上传和导入自定义 Python 代码的能力。
我们还能够以一种以前需要数据在多个工具之间来回传输的方式将 SQL 和 Python 逻辑融合在一起,我们的团队还通过并行处理获得了更高的性能。通过 SQL 和 Python 的这种融合,我们可以在多个 SQL 行上同时运行用 Python 编写的逻辑,将以前的循环操作变成并行处理。例如,以五种不同深度运行我们的聚类解决方案所需的时间与以一种深度运行所需的时间相同。
“Snowpark 使我们能够加速开发,同时降低与数据移动以及为 SQL 和 Python 运行独立环境相关的成本。”
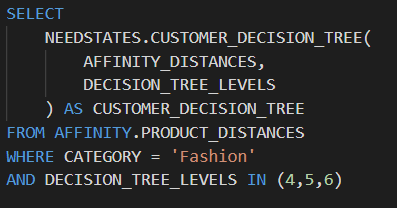
在 Snowflake 中将 Python 函数作为 SQL 语句的一部分运行,包括并行处理
将我们的 Python 进程迁移到 Snowpark 消除了我们架构中不必要的复杂性,并通过删除处理服务之间数据结构变化的所有额外代码来简化了我们的开发。现在,我们的团队可以在数据存储的相同环境中开发、测试和部署他们的 Python 代码,利用 Snowflake 平台的力量,并使用他们首选的开发语言。
HyperFinity 是一款旨在简化决策的软件,它利用强大的数据科学和高级分析技术。Snowflake,以及现在的 Snowpark,是 HyperFinity 架构的重要组成部分,我们对 Snowflake 为软件带来的性能和稳定性以及 Snowflake 发布的新功能,使其工作起来更加强大,感到非常满意。
作为一家初创公司,在 Snowflake 的基础上构建我们的应用程序简化了我们的基础设施和开发过程,并加速了软件的上市进程。